OCR Add-on Settings:
In Docsvault Server Manager dialog, OCR section displays the mode the OCR process is currently in (Trial, Expired or Activated). When in trial mode, you can see the number of trial documents remaining here out of the 100 documents trial limit.
 OCR Options |
OCR Service:
This option will allow you to enable or disable the OCR service.
OCR process runs in the background as a separate service on the machine where Docsvault Server is installed. Docsvault allows you to schedule the OCR process at a pre-defined time window or when the CPU is running below certain load.
Users who need to process large volumes of documents during off hours can use the scheduler function to define the processing time. For example, a company may wish to schedule processing for large volumes of documents during after-office hours so that other essential Docsvault functions (like serving client requests) are not affected by the OCR process during normal business hours.
To process OCR, you must enable the OCR service and set one of the following schedule options:
Normally: Select this option to process OCR at regular intervals (Docsvault will look for new files to OCR every few seconds)
On Schedule between ..... and ...... : On selection this option the OCR process will be executed only between the specified time window
When CPU load is less than ..... % : When this option is selected, OCR process will only start when the CPU usage is less than the specified percentage
If you chose to run the OCR process on a schedule, make sure that the Docsvault server computer is running at scheduled time.
|
Docsvault can also OCR PDF files that were scanned by other applications once they are imported into Docsvault. To enable this feature check the option shown below. Once this option is enabled, Docsvault will perform optical character recognition (OCR) as well as optimize the resultant file size while creating a searchable PDF file. However, if the OCR process finds any text or vector content in any imported PDF file, it will skip that PDF file and will keep it in its original form. This is essential to protect the formatting for text and vector based PDF files that do not need any OCR.
 |
Select this checkbox to automatically OCR TIFF files to searchable PDF files when importing or converting TIFF image files to PDFs in Docsvault.

If the scanned PDF file includes text contents along with images that you wish to OCR, you can force OCR on this PDF by opening the properties dialog of this file in Docsvault Client and marking it for Re-OCR/Force OCR. This will convert the entire PDF file into image based PDF and then OCR all pages.
|
Do not create new version for OCRed files: Select this option to skip new version for OCRed PDFs. The original PDFs will be overwritten with new OCRed PDFs instead of creating a new file version. This is a good option if storage space is limited on the drive that hosts Docsvault data.
This will display the summary of OCR process along with the list of the files in different OCR states.
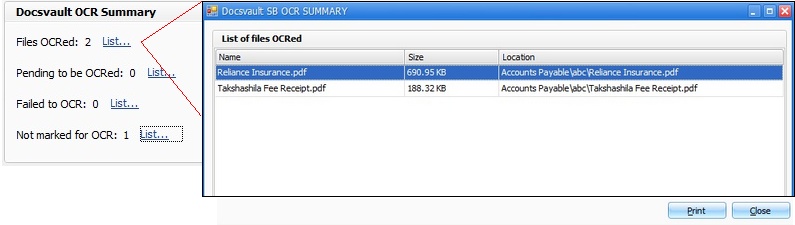 |
You can even mark the files that have not been marked for OCR or failed to OCR for Re-OCR/Force OCR from the respective links.